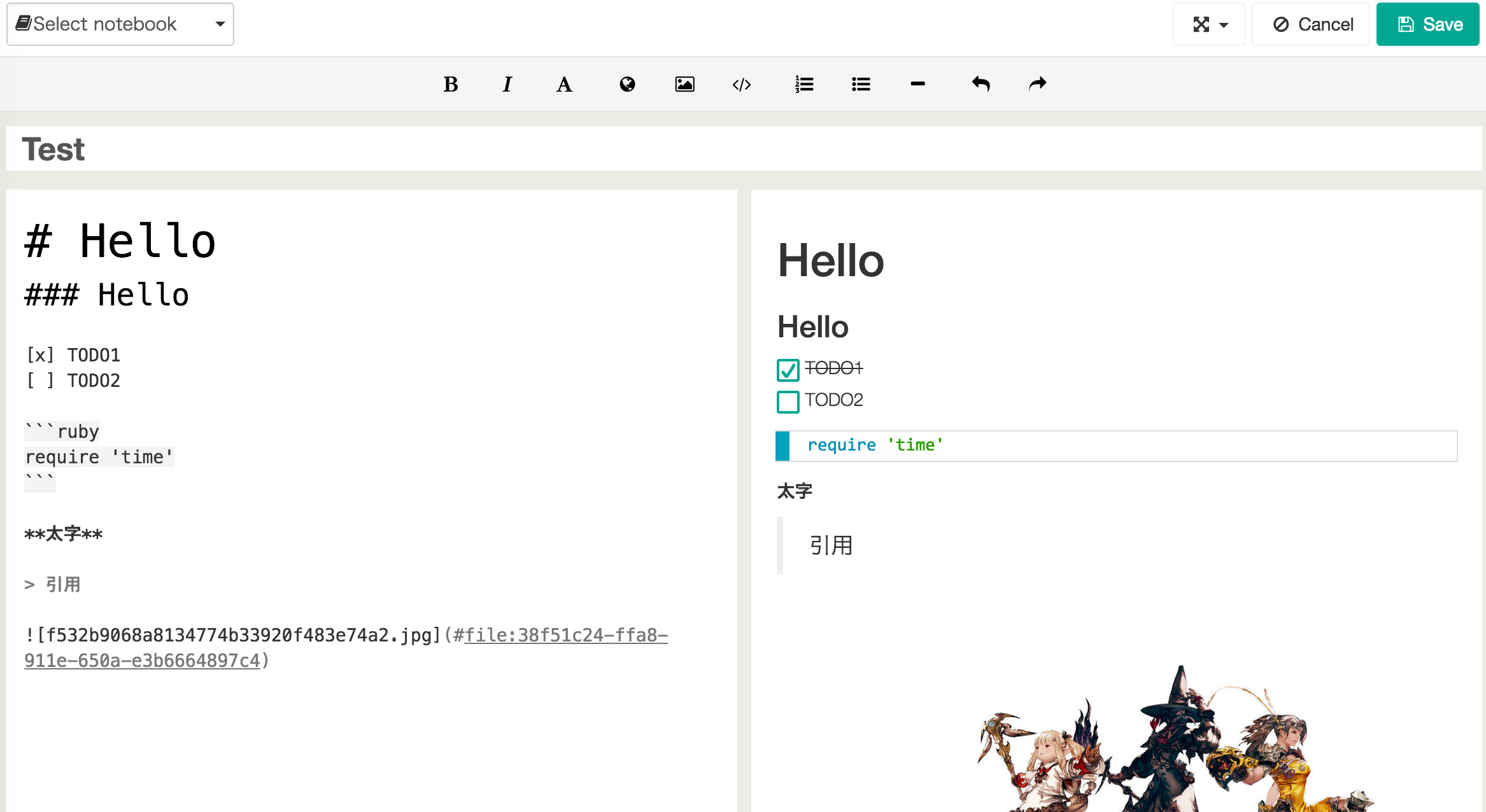
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp USING (campaign_id, campaign_creative_id) FULLOUTERJOIN click USING (campaign_id, campaign_creative_id) FULLOUTERJOIN conv USING (campaign_id, campaign_creative_id) ;
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp USING (campaign_id, campaign_creative_id) FULLOUTERJOIN click USING (campaign_id, campaign_creative_id) FULLOUTERJOIN conv USING (campaign_id, campaign_creative_id) WHERE campaign_id =102
Hash Full Join (cost=257.71..361.29 rows=8 width=96) (actual time=0.051..0.056 rows=1 loops=1) Hash Cond: ((COALESCE(COALESCE(imp.campaign_id, vimp.campaign_id), click.campaign_id) = conv.campaign_id) AND (COALESCE(COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id), click.campaign_creative_id) = conv.campaign_creative_id)) Filter: (COALESCE(COALESCE(COALESCE(imp.campaign_id, vimp.campaign_id), click.campaign_id), conv.campaign_id) = 102) Rows Removed by Filter: 3 -> Merge Full Join (cost=243.22..335.01 rows=1570 width=72) (actual time=0.024..0.028 rows=4 loops=1) Merge Cond: ((click.campaign_id = (COALESCE(imp.campaign_id, vimp.campaign_id))) AND (click.campaign_creative_id = (COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id)))) -> Index Scan using pk_click1 on click (cost=0.15..71.70 rows=1570 width=24) (actual time=0.003..0.003 rows=1 loops=1) -> Sort (cost=243.06..246.99 rows=1570 width=48) (actual time=0.019..0.020 rows=3 loops=1) Sort Key: (COALESCE(imp.campaign_id, vimp.campaign_id)), (COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id)) Sort Method: quicksort Memory: 25kB -> Merge Full Join (cost=0.30..159.72 rows=1570 width=48) (actual time=0.006..0.010 rows=3 loops=1) Merge Cond: ((imp.campaign_id = vimp.campaign_id) AND (imp.campaign_creative_id = vimp.campaign_creative_id)) -> Index Scan using pk_imp1 on imp (cost=0.15..71.70 rows=1570 width=24) (actual time=0.002..0.002 rows=3 loops=1) -> Index Scan using pk_vimp1 on vimp (cost=0.15..71.70 rows=1570 width=24) (actual time=0.002..0.003 rows=1 loops=1) -> Hash (cost=14.37..14.37 rows=8 width=24) (actual time=0.013..0.013 rows=1 loops=1) Buckets: 1024 Batches: 1 Memory Usage: 9kB -> Bitmap Heap Scan on conv (cost=4.21..14.37 rows=8 width=24) (actual time=0.011..0.011 rows=1 loops=1) Recheck Cond: (campaign_id = 102) Heap Blocks: exact=1 -> Bitmap Index Scan on pk_conv1 (cost=0.00..4.21 rows=8 width=0) (actual time=0.008..0.008 rows=1 loops=1) Index Cond: (campaign_id = 102) Planning time: 0.295 ms Execution time: 0.119 ms
WHERE句に全部条件を書いてみる
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp USING (campaign_id, campaign_creative_id) FULLOUTERJOIN click USING (campaign_id, campaign_creative_id) FULLOUTERJOIN conv USING (campaign_id, campaign_creative_id) WHERE imp.campaign_id =102 OR vimp.campaign_id =102 OR click.campaign_id =102 OR conv.campaign_id =102 ;
※今回のケースではANDで繋げるのはNG。とてもひどいことになった気がする。
Merge Full Join (cost=418.50..510.92 rows=31 width=96) (actual time=0.034..0.035 rows=1 loops=1) Merge Cond: ((conv.campaign_id = (COALESCE(COALESCE(imp.campaign_id, vimp.campaign_id), click.campaign_id))) AND (conv.campaign_creative_id = (COALESCE(COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id), click.campaign_creative_id)))) Filter: ((imp.campaign_id = 102) OR (vimp.campaign_id = 102) OR (click.campaign_id = 102) OR (conv.campaign_id = 102)) Rows Removed by Filter: 4 -> Index Scan using pk_conv1 on conv (cost=0.15..71.70 rows=1570 width=24) (actual time=0.006..0.006 rows=2 loops=1) -> Sort (cost=418.35..422.28 rows=1570 width=72) (actual time=0.022..0.022 rows=4 loops=1) Sort Key: (COALESCE(COALESCE(imp.campaign_id, vimp.campaign_id), click.campaign_id)), (COALESCE(COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id), click.campaign_creative_id)) Sort Method: quicksort Memory: 25kB -> Merge Full Join (cost=243.22..335.01 rows=1570 width=72) (actual time=0.015..0.018 rows=4 loops=1) Merge Cond: ((click.campaign_id = (COALESCE(imp.campaign_id, vimp.campaign_id))) AND (click.campaign_creative_id = (COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id)))) -> Index Scan using pk_click1 on click (cost=0.15..71.70 rows=1570 width=24) (actual time=0.001..0.001 rows=1 loops=1) -> Sort (cost=243.06..246.99 rows=1570 width=48) (actual time=0.012..0.012 rows=3 loops=1) Sort Key: (COALESCE(imp.campaign_id, vimp.campaign_id)), (COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id)) Sort Method: quicksort Memory: 25kB -> Merge Full Join (cost=0.30..159.72 rows=1570 width=48) (actual time=0.005..0.008 rows=3 loops=1) Merge Cond: ((imp.campaign_id = vimp.campaign_id) AND (imp.campaign_creative_id = vimp.campaign_creative_id)) -> Index Scan using pk_imp1 on imp (cost=0.15..71.70 rows=1570 width=24) (actual time=0.002..0.003 rows=3 loops=1) -> Index Scan using pk_vimp1 on vimp (cost=0.15..71.70 rows=1570 width=24) (actual time=0.001..0.002 rows=1 loops=1) Planning time: 0.194 ms Execution time: 0.084 ms
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp ON (imp.campaign_id = vimp.campaign_id AND imp.campaign_creative_id = vimp.campaign_creative_id) FULLOUTERJOIN click ON (imp.campaign_id = click.campaign_id AND imp.campaign_creative_id = click.campaign_creative_id) FULLOUTERJOIN conv ON (imp.campaign_id = conv.campaign_id AND imp.campaign_creative_id = conv.campaign_creative_id) ;
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp ON (imp.campaign_id = vimp.campaign_id AND imp.campaign_creative_id = vimp.campaign_creative_id) FULLOUTERJOIN click ON (vimp.campaign_id = click.campaign_id AND vimp.campaign_creative_id = click.campaign_creative_id) FULLOUTERJOIN conv ON (click.campaign_id = conv.campaign_id AND click.campaign_creative_id = conv.campaign_creative_id) ;
SELECT COALESCE(imp.campaign_id, vimp.campaign_id, click.campaign_id, conv.campaign_id) as campaign_id, COALESCE(imp.campaign_creative_id, vimp.campaign_creative_id, click.campaign_creative_id, conv.campaign_creative_id) as campaign_creative_id, COALESCE(imp.imp_count, 0) as imp_count, COALESCE(vimp.vimp_count, 0) as vimp_count, COALESCE(click.click_count, 0) as click_count, COALESCE(conv.conv_count, 0) as conv_count FROM imp FULLOUTERJOIN vimp ON (imp.campaign_id =102AND vimp.campaign_id =102AND imp.campaign_id = vimp.campaign_id AND imp.campaign_creative_id = vimp.campaign_creative_id) FULLOUTERJOIN click ON (vimp.campaign_id =102AND click.campaign_id =102AND vimp.campaign_id = click.campaign_id AND vimp.campaign_creative_id = click.campaign_creative_id) FULLOUTERJOIN conv ON (click.campaign_id =102AND conv.campaign_id =102AND click.campaign_id = conv.campaign_id AND click.campaign_creative_id = conv.campaign_creative_id) ;
期待する結果にならないな.. FULL OUTER JOINは難しい。 そもそも何をしたいかと言うと、WHERE句に書くとJOINした後のフィルタリングなので、JOINする前に必要な情報だけに削ってからJOINしたい。 という事は、campaign_id=102で絞った各テーブルを結合する事になる。
WITH構文
WITH fimp AS (SELECT*FROM imp WHERE campaign_id =102), fvimp AS (SELECT*FROM vimp WHERE campaign_id =102), fclick AS (SELECT*FROM click WHERE campaign_id =102), fconv AS (SELECT*FROM conv WHERE campaign_id =102) SELECT COALESCE(fimp.campaign_id, fvimp.campaign_id, fclick.campaign_id, fconv.campaign_id) as campaign_id, COALESCE(fimp.campaign_creative_id, fvimp.campaign_creative_id, fclick.campaign_creative_id, fconv.campaign_creative_id) as campaign_creative_id, COALESCE(fimp.imp_count, 0) as imp_count, COALESCE(fvimp.vimp_count, 0) as vimp_count, COALESCE(fclick.click_count, 0) as click_count, COALESCE(fconv.conv_count, 0) as conv_count FROM fimp FULLOUTERJOIN fvimp USING (campaign_id, campaign_creative_id) FULLOUTERJOIN fclick USING (campaign_id, campaign_creative_id) FULLOUTERJOIN fconv USING (campaign_id, campaign_creative_id) ;
Amazon Kinesis Analytics console does not support managing reference data sources for your applications. You can use the AWS CLI to add reference data source to your application.